AI become high demanding right now, almost all website and application embed AI in every feature they have. AI or should we called LLM (Large language Model) created by company like openai and gemini gave user access to their LLM using API. This could be exponential usage of AI because we do not require install and setup AI inside our own server.
This time, I will demonstrate how I build application resume AI Parsing from ground to up using nextjs, tRPC and n8n. It’s simple features:
- User able create their own resume from scratch
- Or.. upload resume in PDF file and use this information instead.
Let see how fast and easy to use these framework and services to build an application.
I will talk about each step quick and easy to understand.
Technical Spesification

Framework fullstack:
- Frontend— using Reactjs and Nextjs as framework of reactjs.
- Backend— already included in nextjs.
- Communcation— I’m using tRPC because fullstakc code written in typescript.
Library to help me write code faster
- Prisma—ORM sql for quick database querieng
- Next auth—Fullstack Authentication, it manages database, session, backend, frontend and SSO.
- Shadcn/ui—Headless component tailwindcss
Other service I use
- postgresql—Relational database management system
- n8n—Low-code workflow
- minio—S3 compatible service
- Docker—Container management and deployment
Initiation Application
Thanks to Create-t3-app, I’m able to setup nextjs that already included all thing that I needs:
- Nextjs App structure
- Next Auth basic and SSO discord
- Prisma already integrated with next auth
- tRPC with public and protected routes.
it’s easy and I have no problem using this template. I just need to add shadcn/ui and edit the frontend to create non-boring page.

tRPC help me create quick integration backend and frontend, thanks to their type safety. Next, database creation. I create prisma schema and docker compose for n8n and postgresql. Also, I add init sql to create initial user non-root.
I created some tRPC Routes:
- Route Resume—Manage resume of user
- Route Resume File—Store and retrive file from user, also analyze the file through n8n workflow.
File Storage
I have to store the file of resume somewhere else, since the backend is stateless which mean it does not persist the file becuase of deployment using docker container. So, I’m using local s3 compatible, min.io to store the file and using s3-sdk library for easy migration to other s3 compatible services.

Security concern about these file should configure correctly, I use pre-signed url for upload and download by user, so the user will never get the same url of file. Each user will have their own path inside bucket, so they will never collide each other.
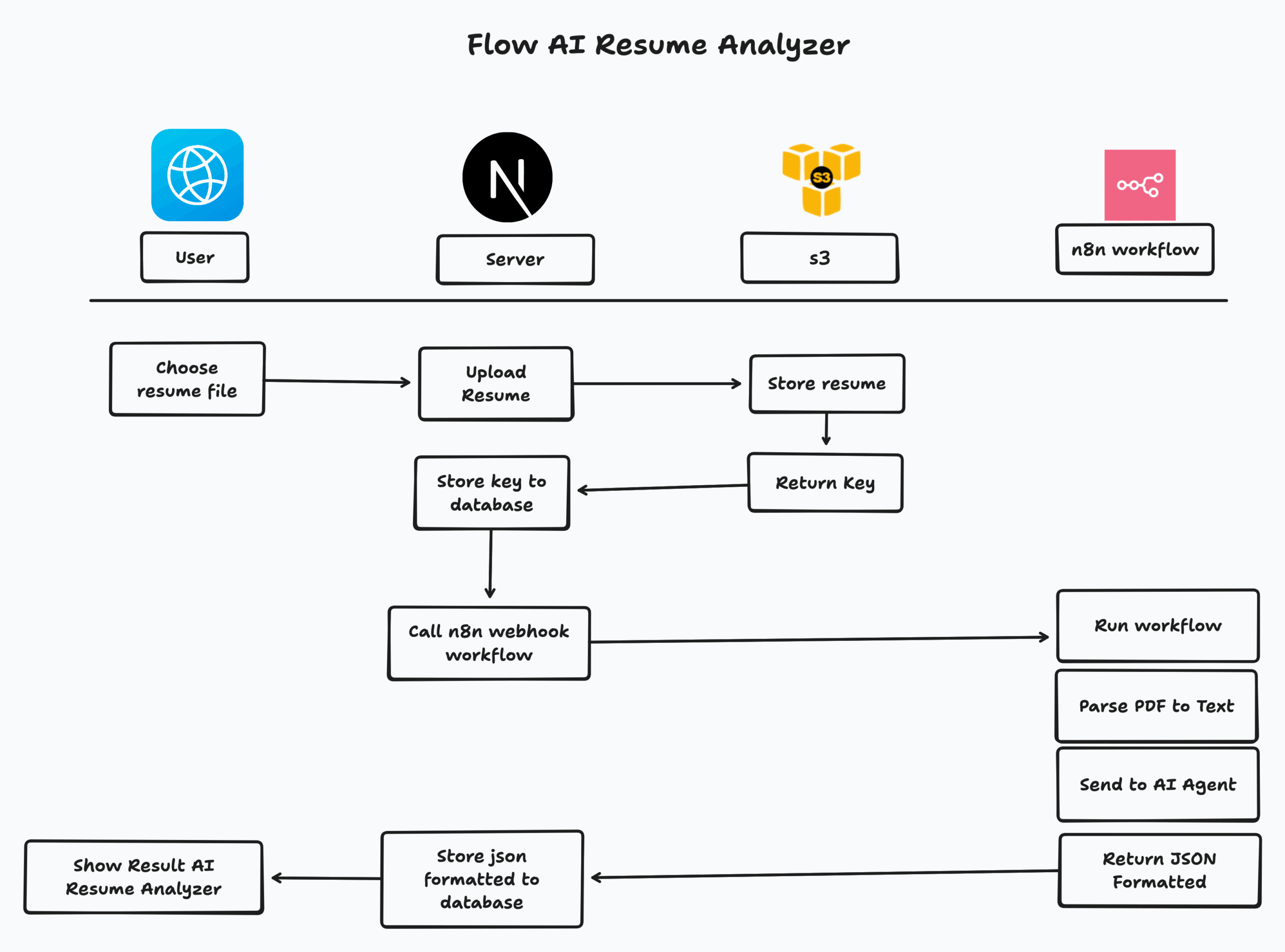
n8n workflow: AI Resume Parsing

Now, the best and crucial part. AI Resume Parsing—I don’t know what exactly name of this agent, but we can use this for now. Basically it’s simple workflow
- Create webhook—without credential because we expect this service run INSIDE network, so we do not worry about authentication.
- Extract from file—Convert PDF to text
- Gemini—Insert extracted text to gemini model (gemma-3n) with this prompt
Analyze the text below and identify resume information.
Format the output as a JSON Object where have all these data:
- name
- phone number
- email
- skills
- experiences (array of `company`, `year`, `description`)
{{ $json.text }}- Code—unfortunately gemini can’t send json formatted correctly, so we have to get our hand dirty to convert those response.
- Last, Response to Webhook
n8n very easy to use, I barely looking to their documentation because all intuitive UI and control.
I tried openai but saddenly I have no money to extend the quota, so I use free usage from gemini. I expect openai able to convert pdf to text directly but we can’t do that. So, we do traditional way.
On the server side, it will use webhook production from n8n to use this workflow. Since we store file resume inside s3 compatible service, now we can retrieve the file directly and send to workflow.

All this process are done in single API:
- User upload their resume
- Analyze resume and put the result into database
- send result to user
Although this process takes couple seconds, but it’s simpler than do async-procces—using server-sent or subscription to wait for workflow to finish. Since we use separete concern of file and code, we could expand the process later or change behaviour to pub-sub to make request-response lighter and quicker. I also add feature to re-analyze if the process failed.
Testing
I’m using my personal Resume for testing purpose
Resume Reference:

AI Agent Result:
[
{
"name": "Rio Chandra",
"phone_number": null,
"email": "me.riochndr@gmail.com",
"skills": [
"Leadership & Project Management: Leadership, Project Management, Team Coordination, Mentoring & Coaching",
"Software Development: Fullstack Web Development, System Architecture, Technical Debt Management, Code Review, Documentation",
"Programming Languages: Python, TypeScript, Go (Golang), Rust",
"DevOps & Testing: CI/CD Implementation, Automated Testing, Database Management",
"Communication & Collaboration: Cross-functional Communication, Stakeholder Coordination"
],
"experiences": [
{
"company": "PT. Kereta Api Indonesia (Persero)",
"year": "2024 – Present",
"description": "Fullstack Developer, Led project lifecycles and coordinated with multiple departments within PT. Kereta Api Indonesia. Initiated the migration of the CI/CD pipeline to GitHub Actions, accelerating the deployment cycle by 60%. Optimized system response time by approximately 99.68%, reducing it from 1 minute to 250 milliseconds. Prepared and delivered weekly progress reports as routine documentation for the project owner."
},
{
"company": "Startup Ezclass.io",
"year": "2024 – August",
"description": "Fullstack Developer, Increased delivery speed by 40% by coordinating the roadmap and strategic documentation. Successfully documented 20 legacy project features into well-structured and easy-to-understand documentation. Reduced technical debt by 40% through workflow optimization, documentation improvements, and implementation of regular testing processes."
},
{
"company": "PT. Sahaware Teknologi Indonesia",
"year": "2020 – January 2023",
"description": "Fullstack Developer, Successfully developed a pharmacy operating system over an 18-month project, now actively used by dozens of pharmacists. Collaborated with stakeholders including Project Owners, Business Development, and Managers to identify challenges and business needs. Led a cross-functional team of 4 Software Engineers, 1 UI/UX Designer, and 3 Quality Assurance specialists. Conducted code reviews, handled maintenance improvements, and consistently ensured on-time project delivery."
}
],
"education": [
{
"degree": "Bachelor’s Degree",
"major": "Information Systems",
"year": "June 2024 – June 2026",
"institution": "Universitas Terbuka, Indonesia"
},
{
"degree": "Diploma (D3)",
"major": "Informatics Engineering",
"year": "March 2017 – August 2019",
"institution": "Politeknik Negeri Bengkalis, Indonesia"
}
]
}
]As you can see, it’s formatted correctly from name, email, skills, experiences, and education even though it has no phone number. Furthermore, the year in experiences field is getting shorted “january 2024-august 2024” becomes “2024-august”.
Here is second test, using standford example that I downloaded

[
{
"name": "Julia Eng-Bachelor",
"phone_number": "(650) 723-0000",
"email": "SUId@stanford.edu",
"skills": [
"Design: SolidWorks",
"Programming: Matlab, C/C++, Java, HTML",
"Fabrication: CNC mill, lathe, brazing",
"Languages: German (conversational)"
],
"experiences": [
{
"company": "Siemens AG",
"year": "6/xx - 9/xx",
"description": "Provided drafting and engineering support at a plant manufacturing drives and motors\nUpdated and maintained electro-mechanical drawings and documentation\nAdhered to best-practice protocols for document control\nObserved factory operations employing precision robots and machine vision"
},
{
"company": "Sigma Delta Tau Sorority",
"year": "20xx - present",
"description": "Led committee that planned and organized monthly events for all 50 women in the house\nOrganized a successful benefit dinner that exceeded fundraising goal (>$5000)"
},
{
"company": "Stanford University",
"year": "20xx - present",
"description": "Tour Guide\nPolished public speaking skills while conducting three campus tours per week"
}
],
"education": [
{
"institution": "Stanford University",
"degree": "B.S. in Mechanical Engineering",
"year": "expected 20xx",
"gpa": "3.7/4.0",
"major": "Mechanical Engineering"
},
{
"institution": "Stanford University",
"degree": "Studied German language, history and culture",
"year": "Spring 20xx",
"location": "Berlin, Germany"
}
],
"course_projects": [
{
"name": "Integrated Compliant Arm-Wrist Robot",
"year": "4/xx - 6/xx",
"description": "Worked on a team to simulate and program an existing robot with 6 degrees of freedom\nEmpirically determined the acceptable gripping pressures for objects of differing shape, weight, and surface texture\nSuccessfully trained robot to pick up and manipulate a delicate wineglass without damaging it"
},
{
"name": "Throw & Catch Robots",
"year": "1/xx - 3/xx",
"description": "Trained twin robots to repeatedly throw and catch a tennis ball\nWorked on a three-person team to simulate and develop the motion and control algorithms\nLed the team in rendering and fine-tuning the algorithms into C++"
}
]
}
]Because the resume is more detailed, AI gave another field like education gpa, major, and course_projects without reducing what already exists. Also the AI smart enough to ignore noise text like “sample”. Here is example Application using the second example:
It match type of the form as expected, but I found inconsistency the result of model AI for phone number property.
Conclusion
Application AI resume parsing just like build another application with extention to n8n workflow for communication to AI agent and customize the flow as we want. It’s a powerful tools to build almost-anything, but I only use it as AI model agent to make thing simple. The obstacles I faces was choose the right model, at first I though any AI Agent accept PDF as document but it’s limited by price and compatibilty. And also not all models are able to response to raw JSON but Markdown-JSON, even though the JSON is formatted correctly.
For future improvement, because of inconsistency result of JSON from AI, we should add more layer of agent to make the JSON formatted correctly everytime. I think n8n is usefull for making flexible asyncronous workflow like reporting, summary AI agent, email delivery, or custom notification. Thanks to their intuitive UI and rich-feature, it’s easy to make anything in here. From this possibility, we can add more feature like ATS, recruitment tracking, find strong candidate, analyze the gap knowledge, level up user with their skills.
Resources
You can find the code on my github repository and workflow n8n inside it too.
Thank you for your reading!